
 The figure to the right shows the basic problem SMDA is trying to solve. Engineers know how to build the plane, and pilots know how to fly it. Both are essential, but they do not always speak the same language.
The figure to the right shows the basic problem SMDA is trying to solve. Engineers know how to build the plane, and pilots know how to fly it. Both are essential, but they do not always speak the same language.
Biomedical data projects have the same challenge. Computational researchers know how to build models, apps, and analysis pipelines. Clinicians and experimentalists know the real-world problem, the constraints, and what a useful tool needs to look like in practice.
SMDA brings these groups together around early, usable prototypes. Our goal is to deploy simple web apps or graphical interfaces quickly, so clinicians and experimentalists can test them, react to them, and shape the design while the computational team continues to build.
Our philosophy is simple: let the computational team build, but let the clinical and experimental team guide the design, use, and testing. In this model, the app is not just the final product: it is the place where collaboration happens.
Shared Tools, Shared Responsibility:
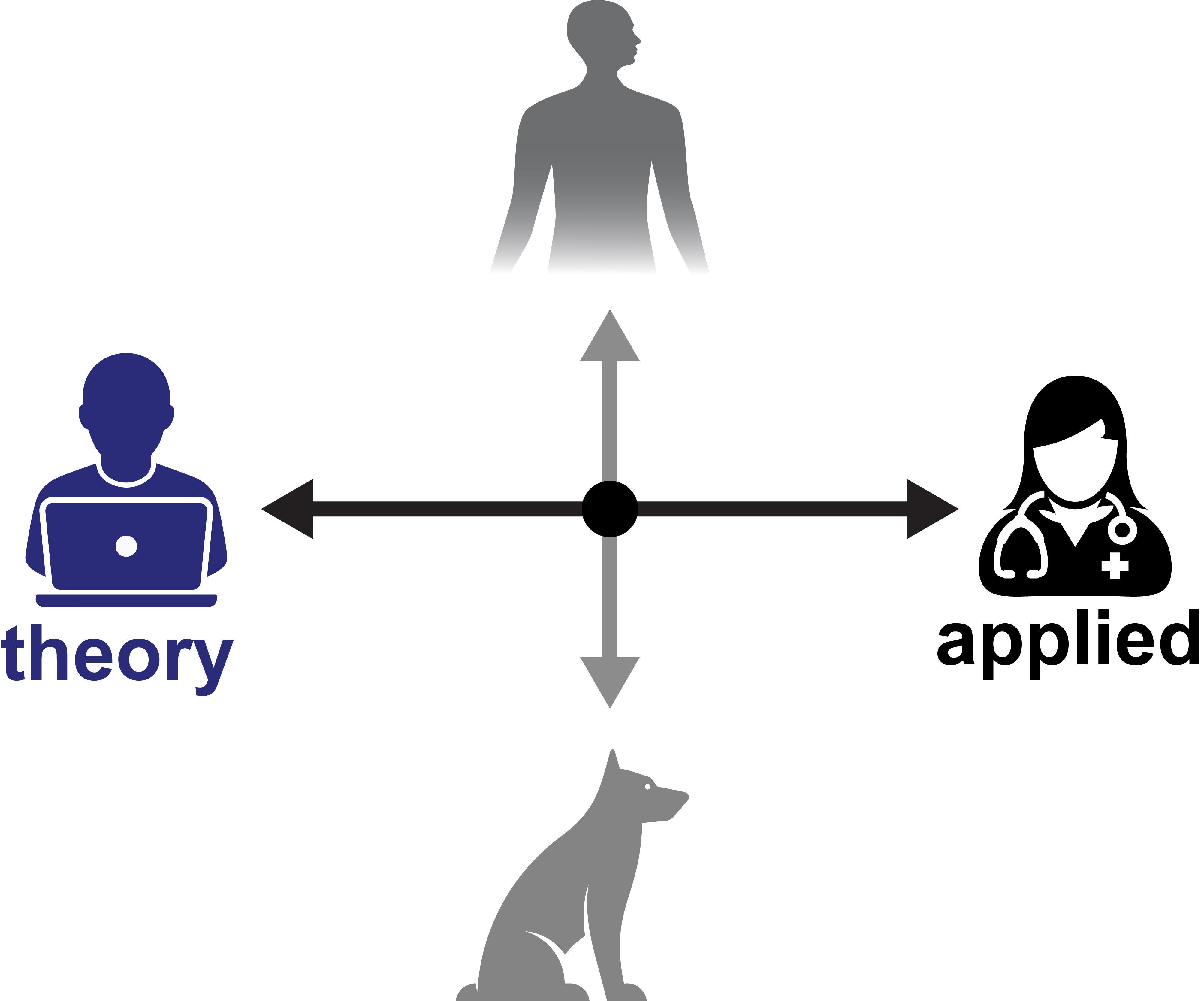 SMDA sits within the Precision One Health Initiative, which places our work at the center of this quadrant system. Our role is to help connect theory with application, and to link human health, veterinary medicine, geography, and ecology through shared data tools. For this reason, SMDA is organized around cross-college working groups that bring together researchers with different expertise around practical, usable projects. Active working groups are listed in the menu bar above.
SMDA sits within the Precision One Health Initiative, which places our work at the center of this quadrant system. Our role is to help connect theory with application, and to link human health, veterinary medicine, geography, and ecology through shared data tools. For this reason, SMDA is organized around cross-college working groups that bring together researchers with different expertise around practical, usable projects. Active working groups are listed in the menu bar above.
SMDA follows a GPL-style philosophy of sharing and community improvement. We believe data tools are most useful when they are open enough for others to test, adapt, and improve. Each working group is therefore organized around shared prototypes, reusable code, and feedback from the people who will actually use the tools. The goal is not just to build one-off projects, but to create resources that become stronger through community use.
As a community, SMDA asks participants to work in the spirit of GPL-style collaboration: use shared tools freely, improve them when possible, and contribute useful changes back to the group. This means giving clear feedback, documenting work so others can build on it, respecting the expertise of both builders and users, and treating prototypes as shared community resources rather than one-off products. The expectation is simple: when the community helps make a tool better, those improvements should remain available to the community.